Snekletter is a weekly newsletter from Pythongasm
🔒
Scrapy is an open-source web scraping framework, and it does a lot more than just a library. It manages requests, parses HTML webpages, collects data, and saves it to the desired format. Hence, you don’t need separate libraries for every other step. You can also use middlewares in scrapy. Middlewares are sort of 'plugins' that add additional functionalities to scrapy. There are plenty of open-source middlewares that we can attach to scrapy for extra features. This article will teach you how to collect data from webpages using scrapy. More specifically, we will be scraping Craigslist, and collect some real state data from their webpage. It would be good to have some prior HTML/CSS experience but you can proceed even if you are not familiar with HTML as a tiny portion of this article has been dedicated to HTML.
Make sure you are running Python 3. Open Terminal, and run the following command:
pip install scrapy
Note
If any permission error shows up, try using sudo.

You won't want to send new requests every time you have to make small changes in your code. Instead, it’s more logical to 'save' the webpage locally with one request, and then see how to call functions, and extract data. This is why we use scrapy shell for debugging. It’s quick, easy and efficient.
Run this command to start the scrapy shell:
scrapy shell
We are scraping real estate section of Craigslist (New York) in this tutorial, which is available here: https://newyork.craigslist.org/d/real-estate/search/rea
Note
You can go to newyork.craigslist.com, and choose real estate from the list of options
We use the fetch() function to, well, fetch the response from an URL.
fetch("https://newyork.craigslist.org/d/real-estate/search/rea")
This will return a HtmlResponse object stored in the response variable.
You can view this response (that is saved locally on the device) in your browser:
view(response)
Let us have a look at this example:

To parse a webpage, we locate elements using the tag name and/or CSS class of that tag. We can instruct our spider to find the h2 tag which has "heading main" as its CSS class, and it will return us this snippet. In this case, there’s only one h2 tag so we won’t even need to specify the class name, we can just tell our spider to look for h2 tag, and it will return us this snippet. If we want to get the span tag inside the h2 tag, we can either get it by specifying the id OR by telling the scraper that we are looking for one that's inside an h2 tag. The goal is to make your scraper uniquely identify the element you are looking for.
Now let us get back to the browser, and find the title of the webpage we just downloaded. Right-click on the webpage, and select Inspect. Titles are generally present inside the head tag.
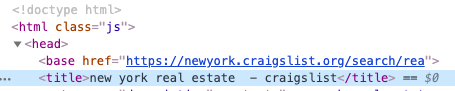
We use this css() function (also called CSS Selector) to select webpage elements. For example, we can select the title tag like this:
[<Selector xpath='descendant-or-self::title' data='<title>new york real estate - craigs…'>]
css() function returns a list (called SelectorList), and each element of this list is a Selector object. There’s only one title tag on the webpage, hence, it's not surprising that the length of this list is 1.
However, this isn't the desired output. We are looking for the text inside the title and not the whole HTML. To get the text inside a tag, we use ::text:
response.css("title::text")
[<Selector xpath='descendant-or-self::title/text()' data='new york real estate - craigslist'<]
You can see that the data in the output has now changed to data='new york real estate', which is the text inside the title tag.
We can get string values from Selector objects by calling get() function on them.
response.css("title::text")[0].get()
'new york real estate - craigslist'
Interestingly, when you call the get() function directly on the list (SelectorList), it still gives you the same output.
response.css("title::text").get()
'new york real estate - craigslist'
This is because when you call get() function without specifying the index, it returns the string value of the very first element in the SelectorList. In other words, you can call get() on a SelectorList, and rather than throwing an error, it calls the get() function on the first element in the list.
We have this another method called getall(). This function simply calls the get() function on every element inside a SelectorList. Hence, getall() function can be called on a SelectorList to obtain a list of strings.

Just like we scraped the title text from the webpage, we can extract other elements from the page using these functions.
Run the following command to start a new scrapy project:
scrapy startproject craigslist
This will create a folder "craigslist" in your current working directory with the following structure:
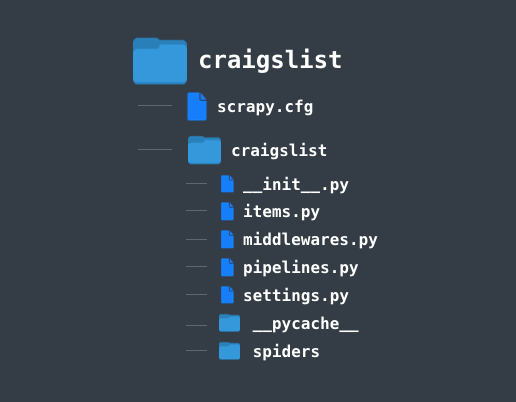
Go to the spiders directory. This is where we will be saving our spiders (crawlers). You can create a new python file in there, and start writing code. However, we can also run the following command to generate a spider with some initial code.
scrapy genspider realestate newyork.craigslist.org/d/real-estate/search/rea
Now open the realestate.py file inside the spiders directory. It should look like this:
# -*- coding: utf-8 -*-
import scrapy
class RealestateSpider(scrapy.Spider):
name = 'realestate'
allowed_domains = ['https://newyork.craigslist.org/d/real-estate/search/rea']
start_urls = ['http://https://newyork.craigslist.org/d/real-estate/search/rea/']
def parse(self, response):
pass
When we run the spider, a request is sent to all the URLs inside start_urls. This is a special variable that automatically calls the parse() function, and passes response as the argument.
parse() function is where we will be writing our code to parse the response. Let us define it like this:
def parse(self, response):
print("\n")
print("HTTP STATUS: "+str(response.status))
print(response.css("title::text").get())
print("\n")
Save the file, and run the spider with this command:
scrapy crawl realestate
HTTP STATUS 200
new york real estate - craigslist
Now, let us extract other elements on the webpage. Inspect the HTML of the first advert. (Right-click > Inspect on the element you want to inspect):

You can see all the information about this advert (tilte, date, price, etc.) is inside this p tag with class name "result-info"

There should be 120 (or equal to the number of listings) such snippets on the webpage.
allAds = response.css("p.result-info")
This will select all such snippets, and make a SelectorList out of them.
Let's try to extract date, price, ad title, and hyperlink from the first advert.
firstAd = allAds[0]
The date is present inside the time tag. Since, there's only one time tag here, we don't really need to specify the CSS class name here:
date = firstAd.css("time").get()
Now extract the title and the hyperlink from the ad, which are present inside the a tag. We need to remove whitespaces in a CSS class name with . :
Note
Whitespaces inside the CSS function represent nesting of tags. Anything separated with a whitespace is considered as a child tag of what's before the whitespace.
title = firstAd.css("a.result-title.hdrlnk::text").get()
link = firstAd.css("a.result-title.hdrlnk::attr(href)").get()
Also, as you can see we add ::attr() in the argument to extract a attributes like src, href from tags.
Finally, we need to find the price which is located inside a span tag with class name "result-price" :
price = firstAd.css("span.result-price::text").get()
Let us complete the parse() function. We just need to loop over the SelectorList, and get the details from Selector objects inside it, as we did with the first Selector object:
def parse(self, response):
allAds = response.css("p.result-info")
for ad in allAds:
date = ad.css("time::text").get()
title = ad.css("a.result-title.hdrlnk::text").get()
price = ad.css("span.result-price::text").get()
link = ad.css("a::attr(href)").get()
print("====NEW PROPERTY===")
print(date)
print(title)
print(price)
print(link)
print(“\n”)
Run this spider again, and you would see an output like this:
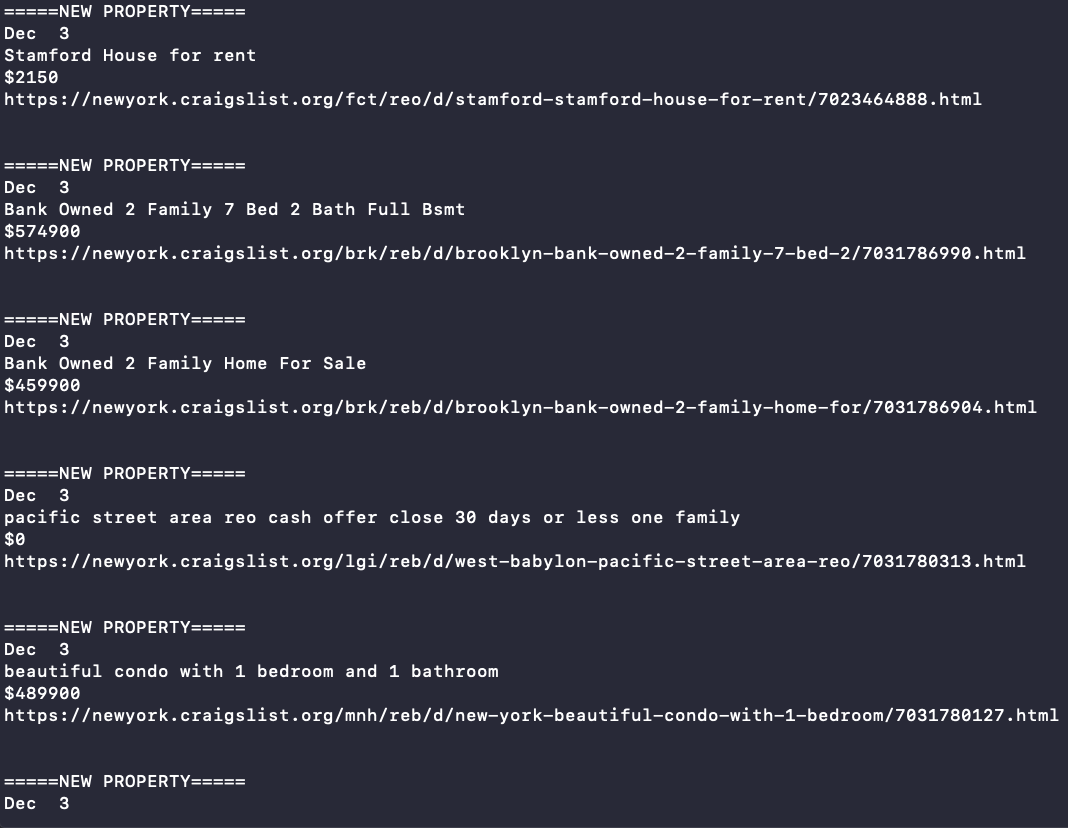
We have successfully scraped the data we wanted from Craigslist. You can always include additional information you might want to extract. With little tweaks, we can also scrape the next few pages of Craigslist (2,3,4, and so on).
Now it’s time to structure it once we have the scraper ready, and make a useful dataset. It’s pretty easy to do it.
Go to Craigslist > Craigslist > items.py
You just need to define new attributes of the CraigslistItem class (It's very much like a Python dictionary class):
import scrapy
class CraigslistItem(scrapy.Item):
date = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
link = scrapy.Field()
Open the realestate.py file, and import the CraigslistItem class from items.py:
from ..items import CraigslistItem
Create an instance of this class, called items, and assign values just like you would do to a dictionary.
def parse(self, response):
allAds = response.css("p.result-info")
for ad in allAds:
date = ad.css("time::text").get()
title = ad.css("a.result-title.hdrlnk::text").get()
price = ad.css("span.result-price::text").get()
link = ad.css("a.result-title.hdrlnk::attr(href)").get()
items = CraigslistItem()
items['date'] = date
items['title'] = title
items['price'] = price
items['link'] = link
yield items
If you are not familiar with the yield keyword, you can read about it here. For now, you can just assume it's doing a job similar to return, but with much more efficiency.
Run the spider with an argument -o output.csv like this:
scrapy crawl realestate -o output.csv
You will find that the output has been saved in the parent directory (Craigslist). Apart from CSV, you can also export the data to other formats like JSON, XML, etc.
Go to craigslist > craigslist > settings.py. This file basically allows you to customise you a lot of things.
For example, before crawling a webpage, scrapy spiders visit the robots.txt file to check permissions/limitations set by the site owner for web crawlers. If a particular page that you want to scrape, is 'restricted' by the website, scrapy won't go to that page. However, you can disable this functionality by simply changing the value of ROBOTSTXT_OBEY to False in the settings.py file, and your crawler will stop following the guidelines inside robots.txt.
Similarly, you can customize user-agent of your crawler (user-agent strings are identifiers through which website recognizes what kind of request it is receiving). You can read more about user-agent here. Let’s say you want to spoof the user agent of Google Chrome (running on macOS). You can assign the a user-agent string to USER_AGENT
USER_AGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36".
This was an introduction to scrapy. As we have already discussed, there are a lot of other things that we can do with scrapy (or web scraping in general). There are many public websites that you might want to scrape, and convert there content into huge datasets for later use (visualisation, prediction, etc.). You can scrape all the tweets made by a user, for example. Hope you enjoyed reading this article.
Built with using FastAPI